X-ray instrument response optimization¶
In this notebook I will discuss some ways to optimize folding a spectral-timing model through an instrument response.
[1]:
import sys
import os
import gc
import numpy as np
from scipy.interpolate import interp1d
import matplotlib.pyplot as plt
import matplotlib.pylab as pl
from matplotlib import cm
from matplotlib.colors import TwoSlopeNorm
import matplotlib.gridspec as gridspec
from matplotlib import rc, rcParams
rc('text',usetex=True)
rc('font',**{'family':'serif','serif':['Computer Modern']})
fi = 22
plt.rcParams.update({'font.size': fi-5})
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath('__file__'))))
from ndspec.Response import ResponseMatrix
rmfpath = os.getcwd()+"/data/nicer-rmf6s-teamonly-array50.rmf"
nicer_matrix = ResponseMatrix(rmfpath)
arfpath = os.getcwd()+"/data/nicer-consim135p-teamonly-array50.arf"
nicer_matrix.load_arf(arfpath)
Arf missing, please load it
Arf loaded
Rebin the instrument response over channels¶
Taking tens of milliseconds to fold a model through a response matrix can be comparable to (or even larger than) the computing time of a typical Xspec models. As a result, careless folding of the instrument response can be a major bottleneck in fitting modern, multi-dimensional data.
In practice however, one never needs 1500 channels when it comes to most X-ray data, particularly for the case of spectral-timing analysis. For instance, typical NICER timing products like lag spectra only use a few dozen energy bins, meaning we can (and should) rebin our instrument response to a grid of a few dozen channels instead. nDspec provides this functionality within the ResponseMatrix object.
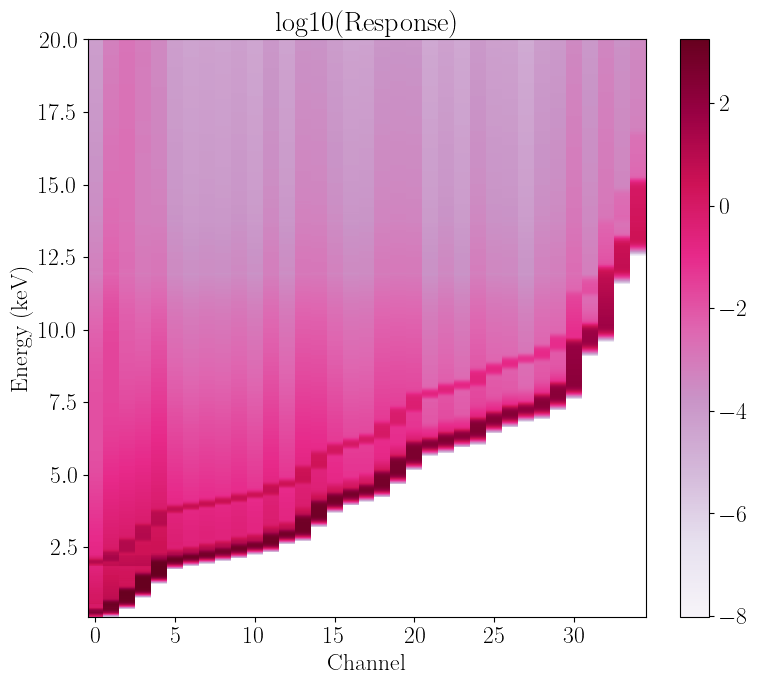
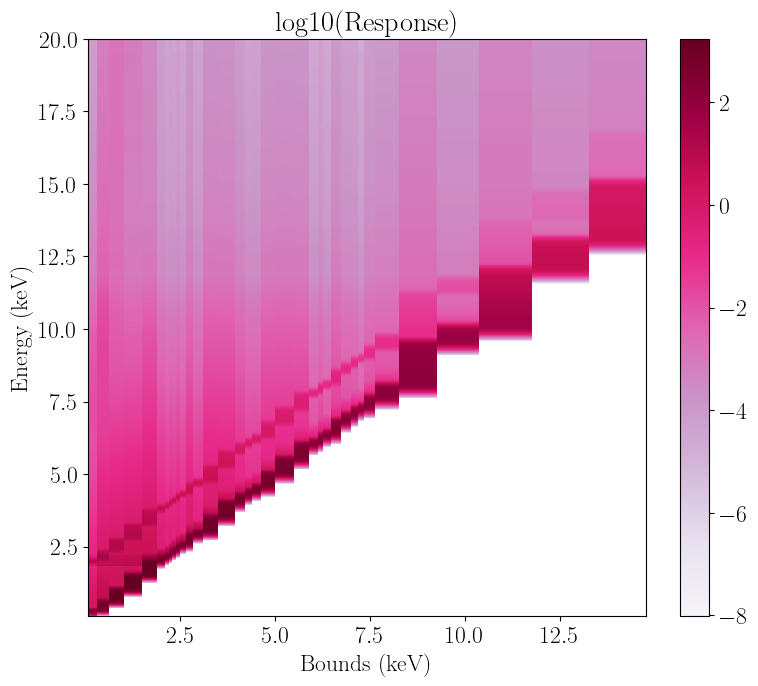
Let us define an arbitrarily spaced new grid of 35 channel bounds. We can then rebin our matrix object with the rebin_channels method to this new, smaller grid made up of only 35 channels. After doing so, let us plot the response again, comparing channel and bounds:
[2]:
#define an arbitrary grid, from arrays of lower and upper energy bounds
new_bounds_lo = np.array([0.1,0.3,0.6,1,1.5,2,2.13,2.21,2.3,2.4,2.52,2.6,2.9,3.,3.5,4.,4.25,
4.4,4.54,5,5.5,6,6.1,6.3,6.4,6.8,7,7.2,7.3,7.6,8,9.5,10.,12.,13.])
new_bounds_hi = np.array([0.3,0.6,1,1.5,2,2.13,2.21,2.3,2.4,2.52,2.6,2.9,3.,3.5,4.,4.25,4.4,
4.54,5,5.5,6,6.1,6.3,6.4,6.8,7,7.2,7.3,7.6,8,9.5,10.,12.,13.,15.])
#rebin the response matrix and plot the resulting new matrix
rebin_chans = nicer_matrix.rebin_channels(new_bounds_lo,new_bounds_hi)
rebin_chans.plot_response()
rebin_chans.plot_response(plot_type="energy")
gc.collect()
/home/matteo/Software/nDspec/src/ndspec/Response.py:515: RuntimeWarning: divide by zero encountered in log10
p = plt.pcolormesh(x_axis,energy_array,np.log10(self.resp_matrix),
/home/matteo/Software/nDspec/src/ndspec/Response.py:515: RuntimeWarning: divide by zero encountered in log10
p = plt.pcolormesh(x_axis,energy_array,np.log10(self.resp_matrix),
[2]:
11356
The response natrix is now much coarser, but for spectral-timing data this is not a problem. Note also how the rough 100:1 mapping of channels to energy, initially present in the response, is no longer there, and in fact it is impossible to directly relate channel numbers to energy bounds. This is purely because we chose a very un-regularly spaced grid.
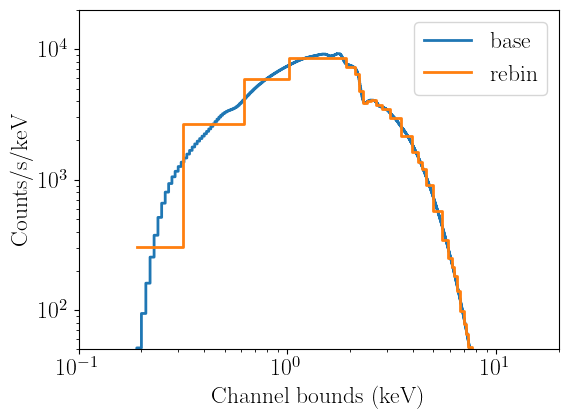
Let us now define a sample spectral model, using a blackbody with a temperature of 1 keV and unity normalization, convolve it with both instrument respones, and compare the two folded models. Note how the rebinned matrix produced a much coarser folded model, but otherwise the count rate at each energy is roughly identical:
[3]:
def bbody(array, params):
#with these defintions, this model is identical to the xspec implementation
norm = params[0]
temp = params[1]
renorm = 8.0525*norm/np.power(temp,4.)
planck = np.exp(array/temp)-1.
model = renorm*np.power(array,2.)/planck
return model
#define the energy bin mid points and widths, from the matrix we just loaded
nicer_grid = 0.5*(nicer_matrix.energ_hi+nicer_matrix.energ_lo)
nicer_bins = nicer_matrix.energ_hi-nicer_matrix.energ_lo
#define the model and convolve it with the response
bb_params = np.array([1.,1.])
bb_model = bbody(nicer_grid,bb_params)*nicer_bins
nobin_fold = nicer_matrix.convolve_response(bb_model,units_in="xspec",units_out="kev")
channel_grid = 0.5*(nicer_matrix.emax+nicer_matrix.emin)
rebin_channel_fold = rebin_chans.convolve_response(bb_model,units_in="xspec",units_out="kev")
rebin_grid = 0.5*(rebin_chans.emax+rebin_chans.emin)
fig, (ax1) = plt.subplots(1,1,figsize=(6,4.5))
ax1.step(channel_grid,nobin_fold,label='base',lw=2,where='mid')
ax1.step(rebin_grid,rebin_channel_fold,label='rebin',lw=2,where='mid')
ax1.set_xscale("log")
ax1.set_yscale("log")
ax1.set_xlabel("Channel bounds (keV)")
ax1.set_ylabel("Counts/s/keV")
ax1.legend(loc='upper right')
ax1.set_xlim([0.1,20.])
ax1.set_ylim([5e1,2e4])
fig.tight_layout()
Now we can benchmark the two convolutions and note that, as we would expect, the re-binned convolution is much faster:
[4]:
from timeit import Timer
print("Unbinned convolution runtime:")
%timeit nicer_matrix.convolve_response(bb_model,units_in="xspec",units_out="kev")
print("Channel rebinning convolution runtime:")
%timeit rebin_chans.convolve_response(bb_model,units_in='xspec',units_out="kev")
Unbinned convolution runtime:
9.63 ms ± 347 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Channel rebinning convolution runtime:
25.3 µs ± 6.81 µs per loop (mean ± std. dev. of 7 runs, 10,000 loops each)
In general, rebinning over channels prevents one from finding fine energy-dependent features in the data, which is almost never the goal with spectral-timing analysis. Therefore, this is the preferred rebinning method to speed up the respones convolution.
Rebin the instrument response over energy¶
Rather than over (arbitrary) instrument channels, it is also possible to rebin a response over physical photon energies. Rebinning to a coarser energy grid has the added bonus of speeding up the computation time of a model (since it has to be calculated over fewer energy bins). However, rebinning to a coarse energy grid can introduce spurious features in the model (and therefore the residuals, once that model is compared to data), so it should generally be done with care if at all.
Let us look at potential issues that might appear. First, the effective area can change noticeably when rebinning over energy. Let us show this by comparing the NICER arf, before and after interpolating it over a coarse energy grid:
[5]:
#define a coarse, geometrically spaced energy grid:
coarse_grid = np.geomspace(0.2,10.,50)
#interpolate over the nicer arf:
interp_obj = interp1d(nicer_grid,nicer_matrix.specresp)
interp_arf = interp_obj(coarse_grid)
fig, (ax1) = plt.subplots(1,1,figsize=(6,4.5))
ax1.plot(nicer_grid,nicer_matrix.specresp,lw=3,label="Arf")
ax1.plot(coarse_grid,interp_arf,lw=3,label="rebin Arf")
ax1.set_xscale("log")
ax1.set_yscale("log")
ax1.set_ylim([1e2,2e3])
ax1.set_xlim([0.2,10])
ax1.set_xlabel("Energy (keV")
ax1.set_ylabel("Effective area (cm$^{2}$")
plt.legend(loc="lower left")
[5]:
<matplotlib.legend.Legend at 0x76f086b34760>
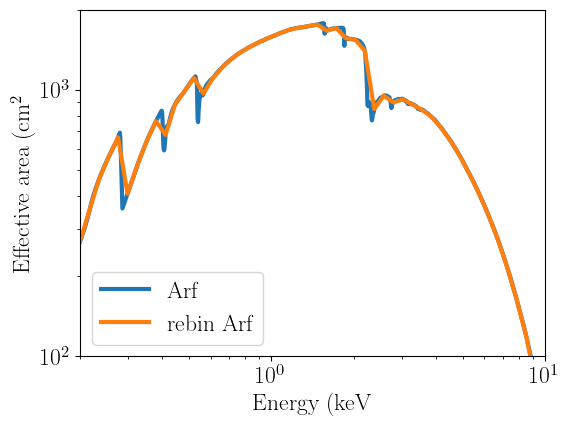
Note how the sharp features are all completely washed out by the interpolation over such a coarse grid. Rebinning over energy can have a similar effect to the interpolation shown above, if it is done aggressively. Let us show this explicitely by taking the NICER response, rebinning it in energy, and comparing the folded models before and after energy rebinning.
In nDspec, a ResponseMatrix object can only be rebinned over energy by integer rebinning - that is, it is only possible to group a fixed number of energy bins together in a new matrix. This is done with the rebin_energy method, which takes as an input the integer factor desired by the user. Compared to allowing for an arbitrary grid this is much safer, as we do not have to deal with a new grid edges potentially not overlapping with the initial ones, and replicates the functionality in
Heasoft.
First, let us calculate the rebinned response for both a coarse and intermediate resolution energy grid, and compare the size of the arrays:
[6]:
rebin_coarse = nicer_matrix.rebin_energies(50)
print("The rebinned energy with coarse resolution grid has a size:",rebin_coarse.energ_hi.shape)
rebin_inter = nicer_matrix.rebin_energies(10)
print("The rebinned energy with intermediate resolution grid has a size:",rebin_inter.energ_hi.shape)
/home/matteo/Software/nDspec/src/ndspec/Response.py:378: UserWarning: WARNING: rebinning a response in energy is dangerous, use at your own risk!
warnings.warn("WARNING: rebinning a response in energy is dangerous, use at your own risk!",
The rebinned energy with coarse resolution grid has a size: (70,)
The rebinned energy with intermediate resolution grid has a size: (346,)
Let us now fold our black body model through these responses, and compare the results to the initial matrix:
[7]:
#define the energy bin mid points and widths, from the matrices we just calculated
inter_grid = 0.5*(rebin_inter.energ_hi+rebin_inter.energ_lo)
inter_bins = rebin_inter.energ_hi-rebin_inter.energ_lo
coarse_grid = 0.5*(rebin_coarse.energ_hi+rebin_coarse.energ_lo)
coarse_bins = rebin_coarse.energ_hi-rebin_coarse.energ_lo
#define the models and convolve them with the response
bb_inter = bbody(inter_grid,bb_params)*inter_bins
energy_inter_fold = rebin_inter.convolve_response(bb_inter,units_in="xspec",units_out="kev")
bb_coarse = bbody(coarse_grid,bb_params)*coarse_bins
energy_coarse_fold = rebin_coarse.convolve_response(bb_coarse,units_in="xspec",units_out="kev")
fig, (ax1) = plt.subplots(1,1,figsize=(6,4.5))
ax1.step(channel_grid,nobin_fold,label='base',lw=3,where='mid')
ax1.step(channel_grid,energy_inter_fold,label='rebin inter',lw=2,where='mid')
ax1.step(channel_grid,energy_coarse_fold,label='rebin coarse',lw=2,where='mid')
ax1.set_xscale("log")
ax1.set_yscale("log")
ax1.set_xlabel("Channel bounds (keV)")
ax1.set_ylabel("Counts/s/keV")
ax1.legend(loc='lower right')
ax1.set_xlim([0.3,10.])
ax1.set_ylim([8e2,1.5e4])
fig.tight_layout()
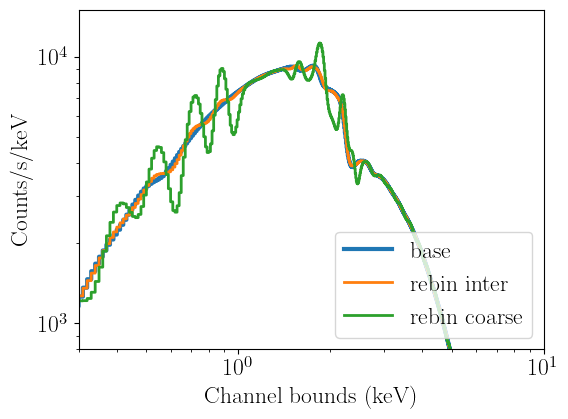
With our extremely coarse grid, we have gone from the 3451 energy bins in the default NICER matrix, to just 70, while keeping 1501 channels. The result of folding a model through this response is the introduction of horrific features that are not present in the un-binned model, and are therefore not physical. This means our energy rebinning was much too aggressive, and is a textbook example of why energy rebinning can be dangerous.
The intermediate grid, instead, has 346 energy bins. In this case, some features are still introduced in the folded model, but they are much less noticeable than with the coarse grid. These may or may not appear as residuals depending on the data quality, so users still need to exercise caution.
Let us now look at what happens when we rebin in both channels and energy:
[8]:
full_rebin = rebin_chans.rebin_energies(50)
full_rebin_fold = full_rebin.convolve_response(bb_coarse,units_in="xspec",units_out="kev")
fig, (ax1) = plt.subplots(1,1,figsize=(6,4.5))
ax1.step(channel_grid,nobin_fold,label='base',lw=2,where='mid')
ax1.step(rebin_grid,rebin_channel_fold,label='ch rebin',lw=2,where='mid')
ax1.step(rebin_grid,full_rebin_fold,label='ch+en rebin',lw=2,where='mid')
ax1.set_xscale("log")
ax1.set_yscale("log")
ax1.set_xlabel("Channel bounds (keV)")
ax1.set_ylabel("Counts/s/keV")
ax1.legend(loc='lower right')
ax1.set_xlim([0.1,20.])
ax1.set_ylim([5e1,2e4])
fig.tight_layout()
/home/matteo/Software/nDspec/src/ndspec/Response.py:378: UserWarning: WARNING: rebinning a response in energy is dangerous, use at your own risk!
warnings.warn("WARNING: rebinning a response in energy is dangerous, use at your own risk!",
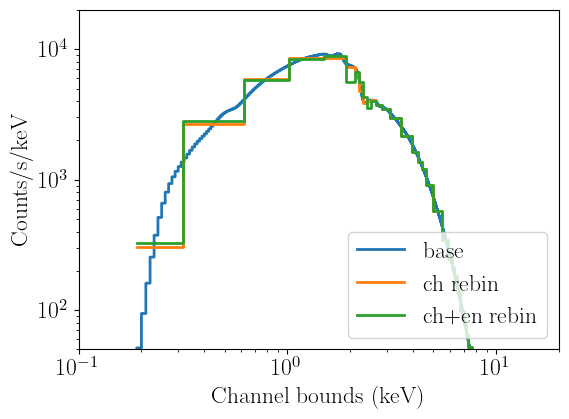
Even with very coarse channel bounds, the very coarse energy rebinning introduces some unphysical features in the folded model, which are especially noticeable around 2-3 keV. Once again, this shows that energy rebinning, if done at all, should be done with care, particularly because the performance gain is much smaller than rebinning in channels:
[9]:
print("Unbinned convolution runtime:")
%timeit nicer_matrix.convolve_response(bb_model,units_in="xspec",units_out="kev")
print("Channel rebinning convolution runtime:")
%timeit rebin_chans.convolve_response(bb_model,units_in='xspec',units_out="kev")
print("Intermediate energy rebinning convolution runtime")
%timeit rebin_inter.convolve_response(bb_inter,units_in="xspec",units_out="kev")
print("Coarse energy+channel rebinning convolution runtime")
%timeit full_rebin.convolve_response(bb_coarse,units_in="xspec",units_out="kev")
Unbinned convolution runtime:
9.52 ms ± 958 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Channel rebinning convolution runtime:
16.4 µs ± 734 ns per loop (mean ± std. dev. of 7 runs, 100,000 loops each)
Intermediate energy rebinning convolution runtime
43.1 µs ± 5.78 µs per loop (mean ± std. dev. of 7 runs, 10,000 loops each)
Coarse energy+channel rebinning convolution runtime
2.55 µs ± 12.7 ns per loop (mean ± std. dev. of 7 runs, 100,000 loops each)
Rebinning responses for two-dimensional models¶
The same considerations also hold for folding two-dimensional models. Let us show this by defining the same impulse response function as in the last tutorial, and then compare the effects of the coarser energy grid:
[10]:
#define our model functions:
def gaussian(array, params):
center = params[0]
width = params[1]
norm = np.multiply(np.sqrt(2.0*np.pi),width)
shape = np.exp(-np.power((array - center)/width,2.0)/2)
line = shape/norm
return line
def powerlaw(array, params):
norm = params[0]
slope = params[1]
model = norm*np.power(array,slope)
return model
def gauss_fred(array1,array2,params):
times = array1
energy = array2
norm = params[0]
width = params[1]
center = params[2]
rise_t = params[3]
decay_t = params[4]
decay_w = params[5]
sigma = width*powerlaw(times,np.array([1.,decay_w]))
fred_profile = np.exp(np.nan_to_num(-rise_t/times)-np.nan_to_num(times/decay_t))
fred_pulse = np.zeros((len(energy),len(times)))
line_profile = np.zeros(len(energy))
pulse_profile = np.zeros(len(times))
for i in range(len(times)):
fred_pulse[:,i] = gaussian(energy,np.array([center,sigma[i]]))*fred_profile[i]
line_profile = np.sum(fred_pulse,axis=1)
pulse_profile = np.sum(fred_pulse,axis=0)
return fred_pulse, line_profile, pulse_profile
#define a time grid and evaulaute the model defined earlier
time_res = 250
time_array = np.linspace(0.1,400,time_res)
norm = 1.
width = 2.5
center = 6.5
rise = 10.
decay = 60.
slope = -0.25
#first define a model with the base energy grid
impulse_base, line_profile_base, pulse_profile_base = gauss_fred(time_array,nicer_grid,[norm,width,center,rise,decay,slope])
#then do the same with the coarse energy grid
impulse_en_rebin, line_profile_en_rebin, pulse_profile_en_rebin = gauss_fred(time_array,coarse_grid,[norm,width,center,rise,decay,slope])
[11]:
colorscale = pl.cm.PuRd(np.linspace(0.,1.,5))
fig = plt.figure(figsize=(9.,7.5))
gs = gridspec.GridSpec(200,200)
gs.update(wspace=0,hspace=0)
ax = plt.subplot(gs[:-50,:-50])
side = plt.subplot(gs[:-50,-50:200])
below = plt.subplot(gs[-50:200,:-50])
c = ax.pcolormesh(time_array,nicer_grid,impulse_base,cmap="PuRd",
shading='auto',linewidth=0,rasterized=True)
ax.set_xticklabels([])
ax.set_xlim([0,400.])
ax.set_ylim([0.1,10.])
ax.xaxis.set_visible(False)
below.semilogy(time_array,pulse_profile_base,linewidth=2.5,color=colorscale[3])
below.set_xlabel("Time ($\\rm{R_g}/c$)",fontsize=18)
below.set_ylabel("Response",fontsize=18)
below.set_xlim([0,400.])
below.set_ylim([1e-1,3e2])
side.step(line_profile_base,nicer_grid,linewidth=2.5,color=colorscale[3],where='mid')
side.invert_xaxis()
side.yaxis.tick_right()
side.yaxis.set_label_position('right')
side.yaxis.set_ticks_position('both')
side.set_yticklabels([], minor=False)
side.set_xlabel("Line profile \n (arb. units)",fontsize=18)
side.set_ylim([0.1,10.5])
side.set_xlim([12.5,-0.5])
fig.colorbar(c, ax=side)
ax.set_title("Energy space model")
plt.show()
gc.collect()
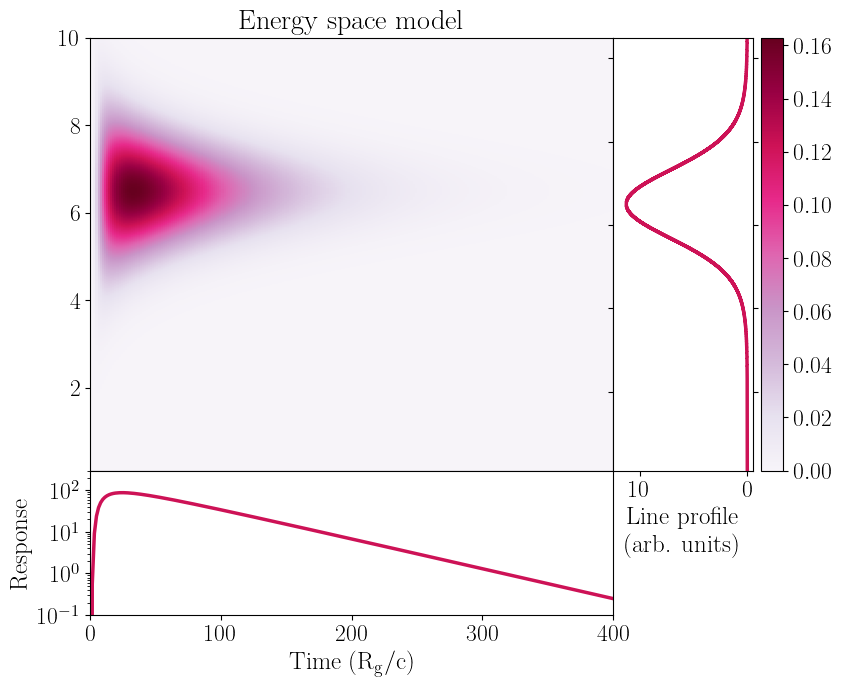
[11]:
19528
[12]:
#and now the low resolution model
fig = plt.figure(figsize=(9.,7.5))
gs = gridspec.GridSpec(200,200)
gs.update(wspace=0,hspace=0)
ax = plt.subplot(gs[:-50,:-50])
side = plt.subplot(gs[:-50,-50:200])
below = plt.subplot(gs[-50:200,:-50])
c = ax.pcolormesh(time_array,coarse_grid,impulse_en_rebin,cmap="PuRd",
shading='auto',linewidth=0,rasterized=True)
ax.set_xticklabels([])
ax.set_ylim([0.1,10.5])
ax.set_xlim([0,400])
ax.set_ylabel("Energy (keV)",fontsize=18)
ax.xaxis.set_visible(False)
below.semilogy(time_array,pulse_profile_en_rebin,linewidth=2.5,color=colorscale[3])
below.set_xlabel("Time ($\\rm{R_g}/c$)",fontsize=18)
below.set_ylabel("Response",fontsize=18)
below.set_ylim([1e-3,4e0])
below.set_xlim([0,400])
side.step(line_profile_en_rebin,coarse_grid,linewidth=2.5,color=colorscale[3],where='mid')
side.invert_xaxis()
side.yaxis.tick_right()
side.yaxis.set_label_position('right')
side.yaxis.set_ticks_position('both')
side.set_yticklabels([], minor=False)
side.set_xlabel("Line profile \n (arb. units)",fontsize=18)
side.set_ylim([0.1,10.5])
side.set_xlim([12.5,-0.5])
fig.colorbar(c, ax=side)
ax.set_title("Energy space model")
plt.show()
gc.collect()
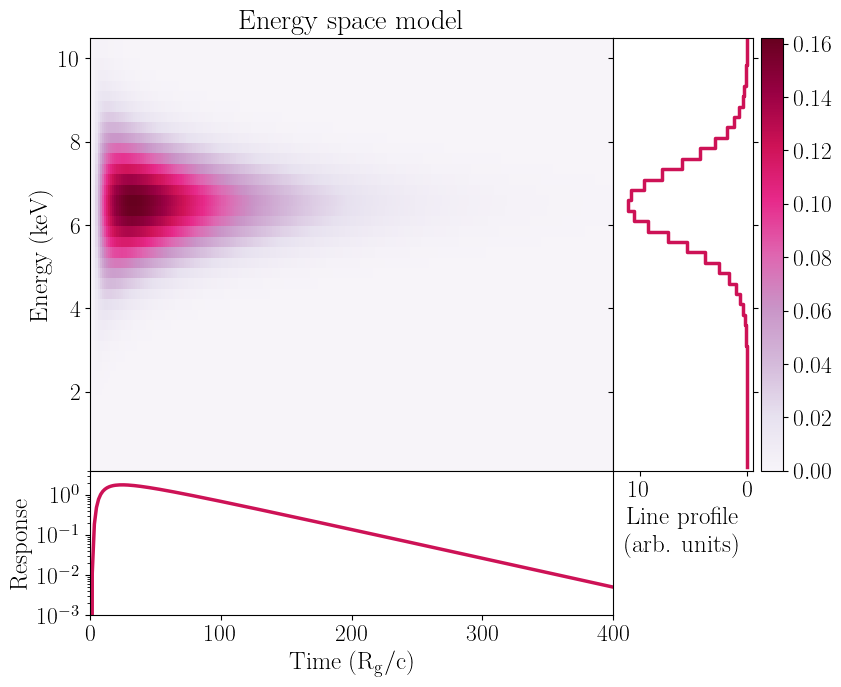
[12]:
14642
We can now fold these two models with the rebinned respones we calculated earlier, and compare the output for each combination.
[13]:
#now let us fold the models through all the rebinned responses, and compare the outputs:
nobin_fold = nicer_matrix.convolve_response(impulse_base,units_in="rate")
channel_fold = rebin_chans.convolve_response(impulse_base,units_in="rate")
energy_fold = rebin_coarse.convolve_response(impulse_en_rebin,units_in="rate")
both_fold = full_rebin.convolve_response(impulse_en_rebin,units_in="rate")
[14]:
#first: plot the unbinned model
convolved_line_profile = np.sum(nobin_fold,axis=1)
fig = plt.figure(figsize=(9.,7.5))
gs = gridspec.GridSpec(200,200)
gs.update(wspace=0,hspace=0)
ax = plt.subplot(gs[:-50,:-50])
side = plt.subplot(gs[:-50,-50:200])
below = plt.subplot(gs[-50:200,:-50])
c = ax.pcolormesh(time_array,channel_grid,nobin_fold,cmap="PuRd",
shading='auto',linewidth=0,rasterized=True)
ax.set_xticklabels([])
ax.set_ylim([0.1,10.5])
ax.set_xlim([0,400])
ax.set_ylabel("Energy (keV)",fontsize=18)
ax.xaxis.set_visible(False)
below.semilogy(time_array,pulse_profile_base,linewidth=2.5,color=colorscale[3])
below.set_xlabel("Time ($\\rm{R_g}/c$)",fontsize=18)
below.set_ylabel("Response",fontsize=18)
below.set_ylim([1e-1,3e2])
below.set_xlim([0,400])
side.step(convolved_line_profile,channel_grid,linewidth=2.5,color=colorscale[3],where='mid')
side.invert_xaxis()
side.yaxis.tick_right()
side.yaxis.set_label_position('right')
side.yaxis.set_ticks_position('both')
side.set_yticklabels([], minor=False)
side.set_xlabel("Line profile \n (arb. units)",fontsize=18)
side.set_xscale("log")
side.set_ylim([0.1,10.5])
side.set_xlim([1e4,1])
fig.colorbar(c, ax=side)
ax.set_title("Detector space model, no rebin")
plt.show()
gc.collect()

[14]:
14724
[15]:
#first: plot the channel-rebinned model
convolved_line_profile = np.sum(channel_fold,axis=1)
fig = plt.figure(figsize=(9.,7.5))
gs = gridspec.GridSpec(200,200)
gs.update(wspace=0,hspace=0)
ax = plt.subplot(gs[:-50,:-50])
side = plt.subplot(gs[:-50,-50:200])
below = plt.subplot(gs[-50:200,:-50])
c = ax.pcolormesh(time_array,rebin_grid,channel_fold,cmap="PuRd",
shading='auto',linewidth=0,rasterized=True)
ax.set_xticklabels([])
ax.set_ylim([0.1,10.5])
ax.set_xlim([0,400])
ax.set_ylabel("Energy (keV)",fontsize=18)
ax.xaxis.set_visible(False)
below.semilogy(time_array,pulse_profile_base,linewidth=2.5,color=colorscale[3])
below.set_xlabel("Time ($\\rm{R_g}/c$)",fontsize=18)
below.set_ylabel("Response",fontsize=18)
below.set_ylim([1e-1,3e2])
below.set_xlim([0,400])
side.step(convolved_line_profile,rebin_grid,linewidth=2.5,color=colorscale[3],where='mid')
side.invert_xaxis()
side.yaxis.tick_right()
side.yaxis.set_label_position('right')
side.yaxis.set_ticks_position('both')
side.set_yticklabels([], minor=False)
side.set_xlabel("Line profile \n (arb. units)",fontsize=18)
side.set_xscale("log")
side.set_ylim([0.1,10.5])
side.set_xlim([1e4,1])
fig.colorbar(c, ax=side)
ax.set_title("Detector space model, channel rebin")
plt.show()
gc.collect()
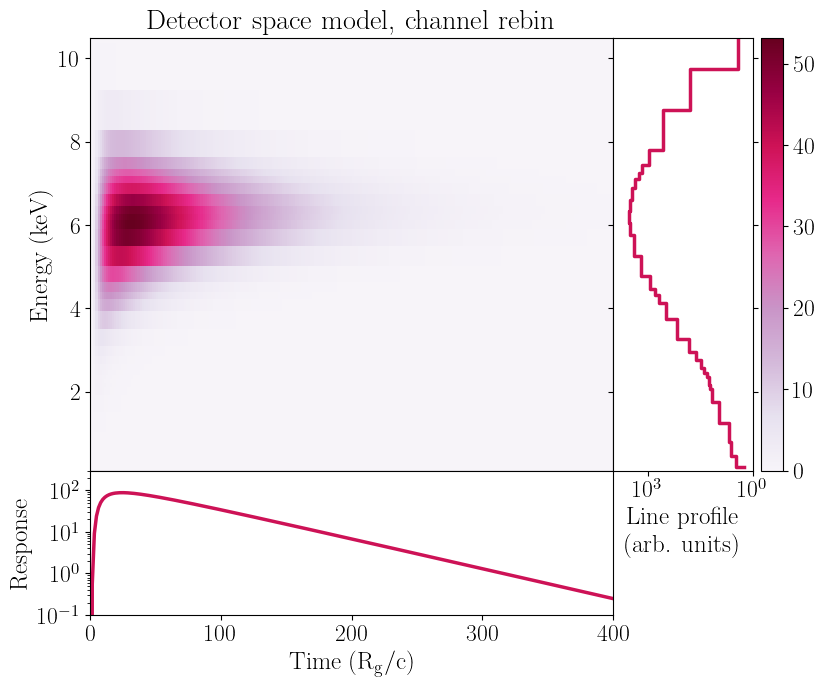
[15]:
14499
Unsurprisingly, rebinning to a coarse channel grid causes the instrumental features to barely appear in the folded line profile.
[16]:
#first: plot the energy-rebinned model
convolved_line_profile = np.sum(energy_fold,axis=1)
fig = plt.figure(figsize=(9.,7.5))
gs = gridspec.GridSpec(200,200)
gs.update(wspace=0,hspace=0)
ax = plt.subplot(gs[:-50,:-50])
side = plt.subplot(gs[:-50,-50:200])
below = plt.subplot(gs[-50:200,:-50])
c = ax.pcolormesh(time_array,channel_grid,energy_fold,cmap="PuRd",
shading='auto',linewidth=0,rasterized=True)
ax.set_xticklabels([])
ax.set_ylim([0.1,10.5])
ax.set_xlim([0,400])
ax.set_ylabel("Energy (keV)",fontsize=18)
ax.xaxis.set_visible(False)
below.semilogy(time_array,pulse_profile_base,linewidth=2.5,color=colorscale[3])
below.set_xlabel("Time ($\\rm{R_g}/c$)",fontsize=18)
below.set_ylabel("Response",fontsize=18)
below.set_ylim([1e-1,3e2])
below.set_xlim([0,400])
side.step(convolved_line_profile,channel_grid,linewidth=2.5,color=colorscale[3],where='mid')
side.invert_xaxis()
side.yaxis.tick_right()
side.yaxis.set_label_position('right')
side.yaxis.set_ticks_position('both')
side.set_yticklabels([], minor=False)
side.set_xlabel("Line profile \n (arb. units)",fontsize=18)
side.set_xscale("log")
side.set_ylim([0.1,10.5])
side.set_xlim([1e4,1])
fig.colorbar(c, ax=side)
ax.set_title("Detector space model, energy rebin")
plt.show()
gc.collect()
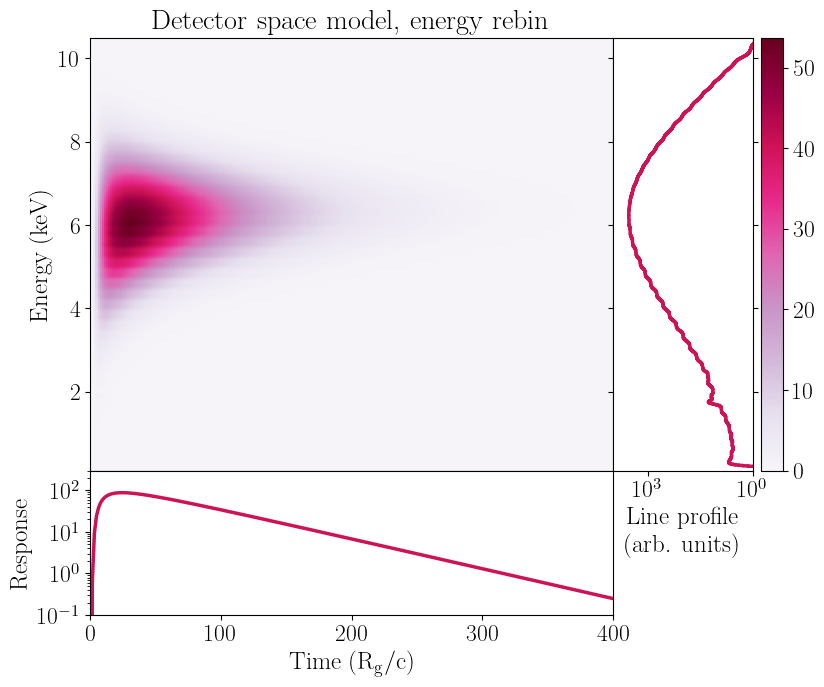
[16]:
14484
Once again, rebinning in energy causes issues in the folded model. Despite the fine channel grid we’re using, there are clear distortions in the line profile that are not present in the unbinned model, and are therefore unphysical.
[17]:
#finally, the channel+energy rebin mode
convolved_line_profile = np.sum(both_fold,axis=1)
fig = plt.figure(figsize=(9.,7.5))
gs = gridspec.GridSpec(200,200)
gs.update(wspace=0,hspace=0)
ax = plt.subplot(gs[:-50,:-50])
side = plt.subplot(gs[:-50,-50:200])
below = plt.subplot(gs[-50:200,:-50])
c = ax.pcolormesh(time_array,rebin_grid,both_fold,cmap="PuRd",
shading='auto',linewidth=0,rasterized=True)
ax.set_xticklabels([])
ax.set_ylim([0.1,10.5])
ax.set_xlim([0,400])
ax.set_ylabel("Energy (keV)",fontsize=18)
ax.xaxis.set_visible(False)
below.semilogy(time_array,pulse_profile_base,linewidth=2.5,color=colorscale[3])
below.set_xlabel("Time ($\\rm{R_g}/c$)",fontsize=18)
below.set_ylabel("Response",fontsize=18)
below.set_ylim([1e-1,3e2])
below.set_xlim([0,400])
side.step(convolved_line_profile,rebin_grid,linewidth=2.5,color=colorscale[3],where='mid')
side.invert_xaxis()
side.yaxis.tick_right()
side.yaxis.set_label_position('right')
side.yaxis.set_ticks_position('both')
side.set_yticklabels([], minor=False)
side.set_xlabel("Line profile \n (arb. units)",fontsize=18)
side.set_xscale("log")
side.set_ylim([0.1,10.5])
side.set_xlim([1e4,1])
fig.colorbar(c, ax=side)
ax.set_title("Detector space model, energy+channel rebin")
plt.show()
gc.collect()
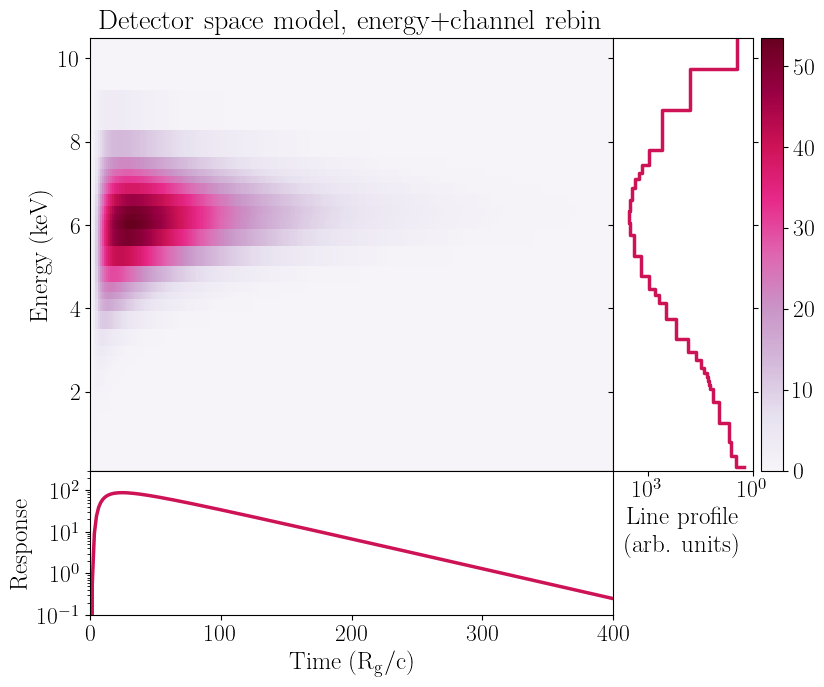
[17]:
14499
Finally, folding with a response rebinned in both energy and channel to a coarse grid behaves somewhat similarly to the channel-rebinned response; however, there are still some small (unphysical) introduced by rebinning in energy. This further reiterates that energy rebinning should be carried out very carefully. Finally, let us compare the performance in each case:
[18]:
print("Unbinned response fold time:")
%timeit nicer_matrix.convolve_response(impulse_base,units_in="rate")
print("Channel rebinned response fold time:")
%timeit rebin_chans.convolve_response(impulse_base,units_in="rate")
print("Energy rebinned response fold time:")
%timeit rebin_coarse.convolve_response(impulse_en_rebin,units_in="rate")
print("Channel+energy response fold time:")
%timeit full_rebin.convolve_response(impulse_en_rebin,units_in="rate")
Unbinned response fold time:
26.4 ms ± 4.88 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
Channel rebinned response fold time:
1.91 ms ± 40.7 µs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
Energy rebinned response fold time:
811 µs ± 101 µs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
Channel+energy response fold time:
75.1 µs ± 7.56 µs per loop (mean ± std. dev. of 7 runs, 10,000 loops each)
Note that in this case energy rebinning does provide a major performance improvement, at the expense of model accuracy as discussed above.
